K-Means Clustering (with Pyscript demo)
Published:
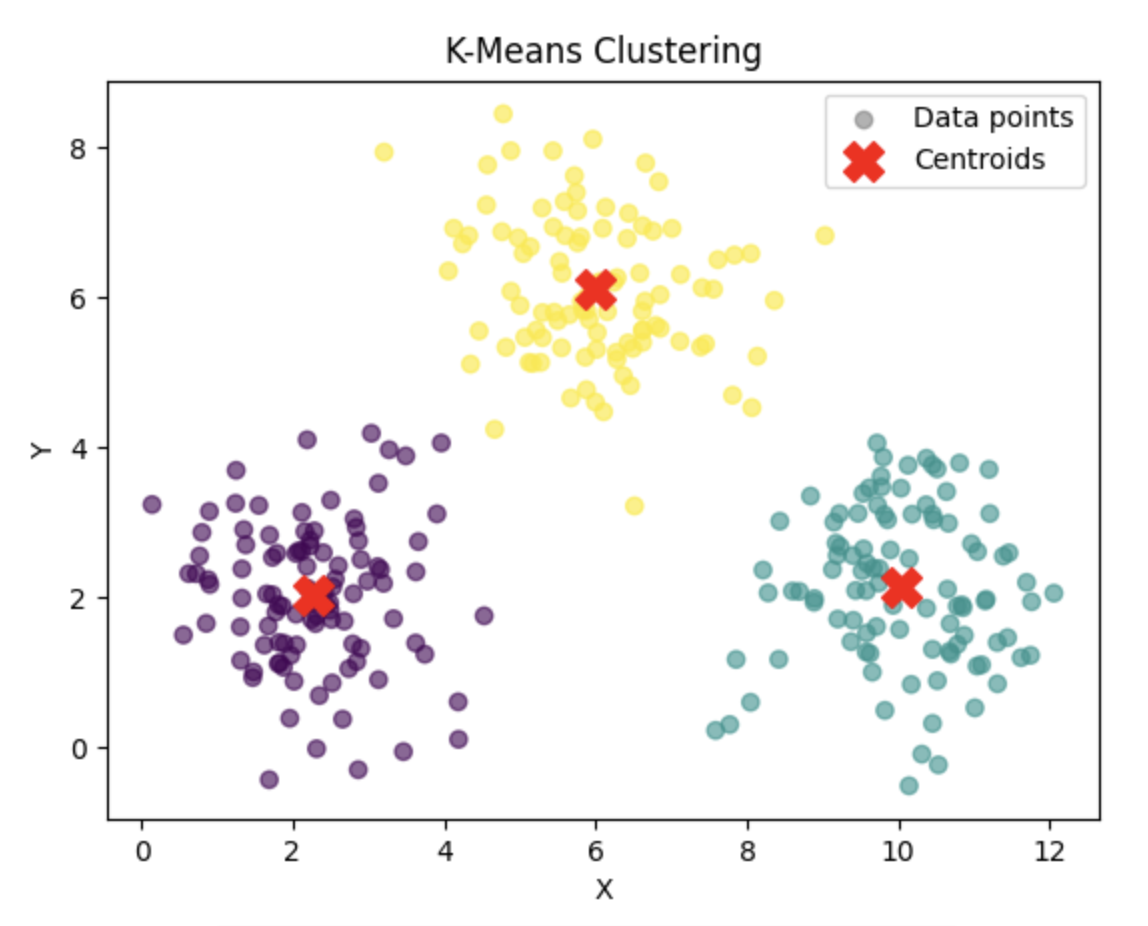
What is K-Means Clustering?
K-Means is a unsupervised learning algorithm used to partition a dataset into \(k\) clusters. The main idea is to group similar data points together (according to a distance metric), minimizing the variance within clusters.
K-Means vs GMM?
Interestingly, K-Means is a special case of GMM (Gaussian Mixture Models).
- Each cluster is spherical, with diagonal covariance matrix.
- The clusters have the same size, with covariance is the same for all clusters
- Hard assignment of each data point to exactly one centroid – instead of data points having probabilities of belonging to centroids.
Algorithm Steps
- Initialization: Randomly select \(k\) points as initial centroids.
Assignment Step: Assign each data point to the nearest centroid based on a distance metric (commonly Euclidean distance). For a point (x_i), the assigned cluster (c_i) is:
\(c_i = \arg\min_{j \in \{1, \dots, k\}} \| x_i - \mu_j \|^2\)
where \(\mu_j\) is the centroid of the \(j\)-th cluster.Update Step: Recompute the centroids of the clusters:
\(\mu_j = \frac{1}{|C_j|} \sum_{x_i \in C_j} x_i\)
where \(C_j\) is the set of points assigned to the \(j\)-th cluster.- Repeat: Iterate between the assignment and update steps until convergence (centroids no longer change or changes are below a threshold).
Python implementation
In this demo, there are three 2D gaussians, and \(k=3\) centroids are initialized randomly as one of the datapoints.